Written by
彭一
on
on
记一次系统优化过程
最近要搞一次抢票活动,就像小米那样,考虑到目前的用户数据,预计到时候会有瞬时30w左右的并发。这对于一个常规的web项目是灾难性的。即可能被宕机。为了解决这种情况,于是对现有系统进行了改造。先说现有系统的结构。
架构优化¶
现有的系统比较简单,属于传统的web应用,架构如下:
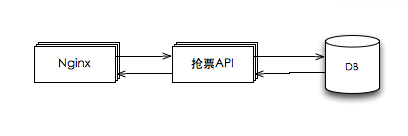
这种架构是最传统的,对于压力不大的情况下,没有任何问题。当压力逐级增大,通过水平扩展 web 服务 和 水平扩展db就达到目的了。但如果瞬时大并发过来,例如:30w/s,也来不及扩展。而且,要求的服务器资源很多,成本不能接受。那么,就要考虑优化和改造了。
30w的瞬时并发,对于后面的压力,主要来源于:nginx,抢票api,db。nginx裸压,轻松上15w并发。所以,nginx只需要有3个就够了。抢票API要水平扩展很多服务器,成本不能接受。而db考虑分库操作,改动比较大,对于现有数据的迁移也是成本。为此,我们只要能解决抢票api和DB的压力就ok了。所以,考虑用MQ解耦。具体架构如下:
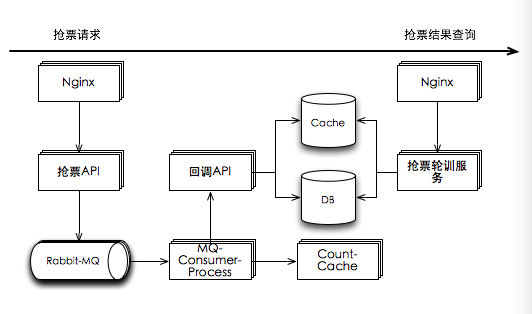
这样子压力转嫁到MQ上。只要抢票API能扛住压力,MQ肯定没有问题。而DB的压力,完全由Consumer的数量决定,是可控的。也就是说,DB完全没有压力。
网络优化¶
网络优化,一般就是优化操作系统的limit fd数量和socket状态。
-
修改 /etc/security/limits.conf。在文件中增加:
* soft nofile 20480 * hard nofile 20480 * - memlock unlimited -
修改 /etc/sysctl.conf
kernel.shmall = 4294967296 net.ipv4.tcp_mem = 786432 2097152 3145728 net.ipv4.tcp_rmem = 4096 4096 16777216 net.ipv4.tcp_wmem = 4096 4096 16777216 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_fin_timeout = 30 net.ipv4.tcp_keepalive_time = 1200 net.ipv4.ip_local_port_range = 1024 65000 net.ipv4.tcp_max_syn_backlog = 8192 net.ipv4.tcp_max_tw_buckets = 5000 net.ipv4.tcp_synack_retries = 2 net.ipv4.tcp_syn_retries = 2 net.ipv4.tcp_max_orphans = 3276800 net.core.netdev_max_backlog = 32768 net.core.somaxconn = 32768 fs.file-max = 1048576